Getting Started
Tex2Speech is a flexible, user-friendly, easy to use text-to-speech web application for converting LaTeX documents to spoken audio (.mp3 format).
GitHubInstallation
To run the application locally, you need to have an Amazon Web Services account. Please create one before continuing. Once you have your AWS account, create/get your AWS access keys which is necessary to make programmatic calls to AWS. You will also need to have Python/Pip installed.
Steps:
- Clone the repository
git clone https://github.com/hutchresearch/latex2speech.git - Create a virtual environment
python3 -m venv envthen run your virtual environmentsource env/bin/activate - cd into latex2speech/tex2speech folder and run the requirements.txt page with the command
pip3 install -r requirements.txtwhich installs other dependencies needed. - Install the AWS CLI by running
pip3 install awsclithen runaws configure, add in your AWS Secret Key and Access Key. When it prompts you region, add us-east-1. - Create a directory called instance in the latex2speech/tex2speech directory. (Keep the instance directory and everything in it private, do not share. This is in the .gitignore)
- Create a file called config.py in the instance directory -> instance/config.py
- Create a variable in config.py called SECRET_KEY and assign it a random generated key (string of random charachters)
- To run the project locally run
python3 application.py
Demos
Demo here
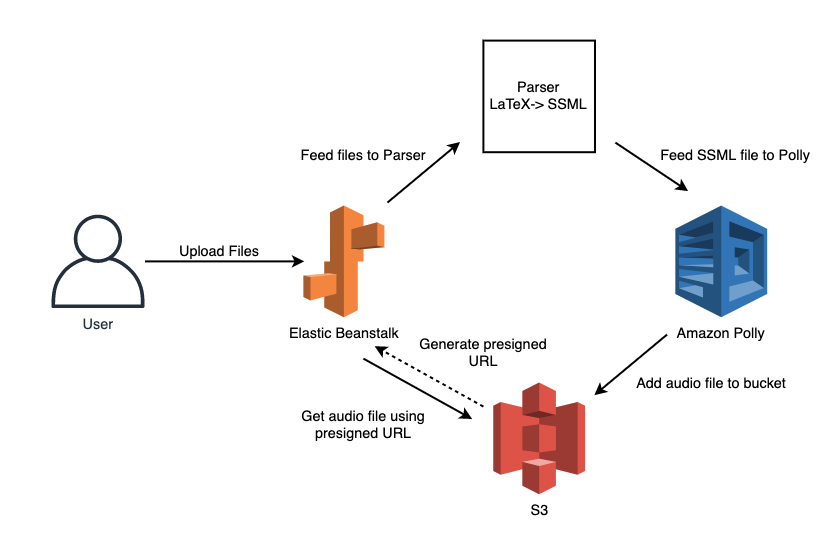
Architecture
Our application is built using the Flask framework. The user will interact with our web application and upload their files that they want sythesized. Once the application receives the files from the user, the files will be pre processed and then given to our Parser.
The Parser converts the LaTeX document into Speech Sythesis Markup Language (SSML). SSML is used since it's a markup language for speech sythesis applications. It allows us to control how words, sentences are pronunced and gives us more control of how the document will be read.
Once the Parser converts the files to SSML format, the new SSML document is fed to Amazon Polly which converts it into a .mp3 file. Then stored into an S3 bucket. To access the .mp3 file, a generaged presigned URL is created so the user can interact with the S3 bucket temporarily to grab their audio file which they can then download.
Note: Elastic Beanstalk is used in production matters, currently we do not have the application running on this instance.
Web Application
The Web Application module is what the user will use to interact with our Tex2Speech application. It has many functions such as:
- Users upload LaTeX (.tex), .zip, .tar, and/or .bib files
- Allow users to configure pronunciation settings (eg., pronounce quantities in mathmode, change voice)
- Feed the files to the rest of the parser
- Grab the audio links and display them to the user on the download page
Pre Processesing
Pre processing is done right after the user hits submit when they upload their necessary documents. What's being done in this small module is it's getting all the documents ready to be fed into TexParser. Some actions that the pre processing module does is as follows:
- Sperates out main tex files, input tex files, and bib files
- Expands comments /* */ in LaTeX
- Expands labels using pdflatex to generate aux file
- Expands out LaTeX macros for TexParser
- And more
Tex Parser
The TexParser is what converts the LaTeX files into SSML files. Its function is similar to a LaTeX to pdf compiler, except that its goal is to parse LaTeX into a stream of text, marked up with SSML, for use in text-to-speech generation. To do this, we use the help of TexSoup to easily navigate and modify the LaTeX documents. The input LaTeX files into TexParser have been preprocessed through the previous module.
Storing Supported LaTeX Commands
We designed a system that was both robust and flexible enough to effectively cover many possible conversion scenarios, while still being feasible to implement. An external XML file is used to actually specify how every command, environment, and command within an environment should be said via SSML. To use this XML file, we decided on creating a MVC design that used an intermediate database to handle all parsing of the XML file. This is not only done to separate code and leave flexibility to change the database implementation, but the conversion database also creates all the SSMLElement objects that are used to create the SSMLElement tree.
Creating an intermediate SSMLElement tree from our own proprietary objects was a decision made for the following reasons:
- Both the LaTeX that the parser will reference and the eventual desired output will be in the form of trees (accomplished with TexSoup for the LaTeX and python's ElementTree package for the output XML).
- More advanced resolution of nested elements requires us to create our own tree structure to manually decide how to resolve each nested element.
- It allows us to decide what common SSML elements we'll have to support
- Creating our own classes allows us flexibility to design classes for solving implementation specific problems as they arise.
SSMLElements were designed with their eventual final form as a python ElementTree in mind, the most significant consequence of which is the headText and tailText attributes. This has a 1 to 1 correspondence with how the ElementTree package stores text within/after a XML node, and so makes it easier for us to convert each node to an XML node afterward. The structure of the classes used in the SSMLElement tree are noted in the following UML diagram:

Pronunciation XML Structure
Under the root LaTeX node there can be either <cmd> or <env> tags. The corresponding name must be specified as an attribute. The type corresponds to whether it is a table command or mathmode command. If it is not, leave it blank. The family attribute corresponds to configurations. For example LaTeX commands: emph, textbf, em are all type 'bold'. So in these three commands we would have family = "bold".
Inside the cmd nodes any SSML elements can be used, along with the tags <text> or <arg>. Inside env nodes there are two separator tags called <says> and <defines>, where <says> defines how the environment will be read out and <defines> defines (or redefines) commands within the specific environment. Within the <says> tag, a <content> tag must be used to denote the relative position of the environments contents.
Example XML Definition
Sample
<latex>
<cmd name=”foo” type = "none" family = "">
asdf
<prosody strength=”strong”>
more text
<arg num=”2”/>
</prosody>
<arg num=”1”>
</cmd>
<env name=”bar” type = "none" family = "">
<says>
<break time=”3ms”/>
qwerty
<content/>
<arg num=”3”>
</says>
<defines>
<cmd name=”baz” type = "none" family = "">
buz
</cmd>
</defines>
</env>
</latex>
From the following LaTeX...
\foo{a}{b}
\begin{bar}{c}{d}{e}
I’m just some text
\baz
\end{bar}
... the parser should generate ...
<speak>
asdf
<prosody strength=”strong”>
b
</prosody>
a
<break time=”3ms”/>
qwerty
I’m just some text
buz
e
</speak>
Mathmode
The mathmode component is what renders LaTeX math commands into SSML format. When TexParser encounters a command that is of type mathmode, the following statement will be thrown into the mathmode component for proper SSML rendering.
Building off of augustt198 latex2sympy project. We use ANTLR to convert the LaTeX mathmode into Sympy objects. Then we convert the Sympy objects into the proper SSML format.
The Sympy to SSML portion of this mathmode parser uses XML and the sympy library to parse each object. Documentation in regards to the XML structure can be shown below. When parenthesis are encountered within each sympy math object, we add start parenthesis and end parentheses within the document to ensure that our users can comprehend a math equation.
Sympy To SSML XML Structure
Each sympy object supported by sympytossml is represented by an entry in static/sympy_funcs.xml. The tag of this entry must be the name of the sympy class, which can be found on docs.sympy.org. The program will use this entry to parse through the function in a linear fashion. It parses through the XML tags and the args array of the Sympy class in parallel, so the first instance of in the XML element is always the first argument in the Sympy args array, unless it is after a <repeat /> tag.
XML Tags
<text>
Anything inside this tag will be appended to the final string in its entirety. There should be no spaces before or after the text
<arg \>
An argument from the sympy function.
<subarg \>
An argument from a subarray within the sympy function's main arg array. See Sum for an example.
<repeat \>
Sets the repeat point. If this tag is present, when the parser reaches the last XML element, it will loop back here until the end of the Sympy args array is reached.
As a convention, text at the beginning of a function does NOT start with "the". For example: <text>integral of</text> , NOT <text> the integral of</text>
Example:
<!--Name of sympy class that represents addition-->
<Add>
<!--Allows an arbitrary number of arguments-->
<arg />
<!--Everything below this tag will be repeated until there are no more args-->
<repeat />
<!--No spaces before or after 'plus'-->
<text>plus</text>
<arg />>
</Add>
Post Processing
Post processing is necessary after the document is in SSML format. Currently, we have it set to get rid of some various tags. This is due to the fact that some charachters do not process in Amazon Polly and mess up it's rendering causing the file not to render.
Speech Sythesis
The speech sythesis module is what feeds the SSML document into Amazon Polly, outputs to an S3 bucket, and creates the presigned URL so the user can temporarily access their audio file. This is within the aws_polly_render.py file. After the document gets marked up from TexParser, if the LaTeX file has a corresponding .bib file with it, this is when it gets properly rendered into SSML. The reason we don't render the .bib during TexParser is because the .bib is not LaTeX and TexParser that uses TexSoup only expands LaTeX commands.
Features
Features here
Testing
Extensive unit testing was performed resulting into 77% code coverage. In the future this will be expanded upon. Since we were using python, we created tests using the built-in unittest module, and then used pytest to discover all the tests in the project. We used Test Driven Development (TDD) and BDD to perform seperate tests.
Integration Testing
For integration testing, our primary concern was testing the robustness of our system against the complexities of the LaTeX language. These complexities stem from LaTeX being a highly extensible macro-based language with thousands of user created libraries, along with most LaTeX files being peppered with small syntax errors due to how robust modern LaTeX compilers are. Given these difficulties, we took a broad approach to testing and did integration testing against a massive 122,000 LaTeX files sourced from ArXiV.org. We were able to create a script that automatically ran our full integrated system against these files and logged the results to help with debugging. The only components not included in these tests were the expensive API calls to Amazon Web Services (AWS). Since these calls are only invoked at the very end of our full system, we believe our test results to be a reasonable proxy to our app’s performance, but note that future integration testing with these calls would be beneficial. The results are as follows:April 20, 2021 - The script was run for a full 24 hours, managing to run through only 12,219 files through. We ended the test at this point since only 30.88% of the files ran without major errors and the logs gave us enough information to start a bug-fixing sprint. The error logs associated with this test can be found here.
May 4, 2021 - With most of the bugs from our previous test now fixed, we ran our program again through as many files for a day. These new changes yielded a 68% success rate, and useful information was documented about bugs still present. A walkthrough of these remaining bugs are listed in the bug section of this document.
User Testing
Since our program produces synthesized human speech as its output, automated testing was far from enough to ensure proper program behavior. The synthesized speech must preserve as much of the paper’s relevant information as possible while simultaneously discarding commands and environments that specify information irrelevant in a listening context. To accomplish this, we performed manual user verification, having each team member listen to a small subset of documents from our 122k LaTeX files and make notes about both where it succeeded and where it struggled. We brought these results on a weekly basis to our client, and used this information to determine how we would further iterate on the software.These tests were performed from May 5 to May 25, and revealed consistent small pronunciation errors in our supported commands and environments, especially within math mode environments. These discoveries forced us to switch from expanding our apps scope to instead focus on improving how the most common commands and environments were pronounced. Typical pronunciation in LaTeX files improved greatly after this, with some of the greatest improvements and challenges occurring in pronunciation of math mode. You can read about our current errors below.
Bugs & Errors That Occur
Bugs are things that shouldn’t happen or need to be fixed, but don't cause the LaTeX file to not properly render. Errors cause the software to terminate execution. Please note the error_log shows a `utf-8` can’t decode byte error. This occurs 22.21% in our failed parsings. This isn’t a concern, and should be taken out of the equation of failure, since this just means that our parser couldn’t grab the contents of the file which is on the file, not our parser.
TexParser Errors/Bugs
Commands That Don’t Use { } Bug
Certain commands such as \item, {\emph stuff}, etc which are not in the traditional format of \command{} do not work well with our parser. \item is currently temporarily done with an if statement to find \item and add all contents afterwards. However, this is not a good solution since there could potentially be nested commands/environments/mathmode that needs to be rendered. {\emph stuff} is a problem since when our parser goes through this, it does not put emphasis tags around the “stuff” component.Expected “x”, reached end of file Error
This is 25.96% of the errors that have currently occurred. Essentially, there are multiple LaTeX commands \newc, \def, \newcommand that users write at the top of their files. These commands allow them to replace a regular environment with a smaller one. For example \newcommand{\beq}{\begin{equation} means that in this LaTeX document, I can use \beq instead of typing out \begin{equation}. However, because of this, when TexSoup sees \begin{equation} in these newcommand, def, etc it gets confused. It believes there should be an associated closing tag, but it can’t find it in the correct position and errors out.Command \item invalid in math mode Error
Occurs 16.45% of the time, from file h2625.tex this occurs when \item is nested within \begin{list}{} \end{list}. There shouldn’t be any math mode involved, could be erroring at that extra {}.Expected “x”, instead got “y” Error
This occurs 4.79% of the time in current files that are erroring. So far, we were able to lessen the occurrence of this error due to some backslash commands that didn’t give a command/environment white space.Malformed Argument Error
Occurs 11.60% from current tests, there are multiple problems that cause this, an example that causes this, is there isn’t enough whitespace between commands. For example \def\t{theta}\def\T{Theta} error out due to this. Instead of them being side by side, the want to be in the following format:\def\t{\theta}
\def\T{\theta}Uncaught Errors
12.19% of errors are currently uncaught.Other Errors
Remaining 6.8% of bugs. There are other errors that were not mentioned on this list from our error_log. You can view them in the \Documentation\GenerateErrorLogs\parse_data\error_log.txt, and they do not occur often, which could mean they are edge cases.Mathmode Errors/Bugs
In Proper Math Mode Input Bug
Our math mode implementation was ensuring that users would enter ‘proper’ math mode conditions. However, from listening to documents it was realized that users use other characters and commands in math mode for formatting. Sometimes, this confuses our parser which results in incorrect audio for that math expression or a math did not render output. An example of this is, some users would write `$s_2$` which would be read as s underscore two. What was quite common in current LaTeX files, was users would instead write `s$_2$`.This is quite common with other math mode commands, where the current parser for math mode that is implemented does not recognize one sided expressions. These expressions include, but are not limited to: $_2$, $^2$, $> 2$, $< 2$, $= 2$.
Since our current implementation only supports basic math mode commands, harder math mode equations sometimes result in an error in the math mode parser which could be expanded upon.
Infinite Loop Error
This has been happening very rarely, out of 13,000 files only 2 were found to have an infinite loop. This had to do with mathmode \gcd{} components. Current commands that we know infinite loop: $\gcd(n, r) r$ and $\gcd(C) := \gcd(T_1, \dotsc, T_k)$.Limit Function
When testing limit functions, extra characters are being added to the end of the mathmode rendering. This is due to the Sympy library.Other Errors/Bugs
Unicode Bug
Windows machines will not render some files/zipped files. Looking inside the log this has to do with the windows file system and also due to Unicode errors. Our application was mainly tested on a Linux Shell and MAC operating system which works fine. Here is the logging error of a specific bug:
[Mon May 24 01:19:42.135628 2021] [:error] [pid 3286] [remote 172.31.93.62:1509] return codecs.ascii_decode(input, self.errors)[0]
[Mon May 24 01:19:42.135637 2021] [:error] [pid 3286] [remote 172.31.93.62:1509] UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 1814: ordinal not in rang(128)
Contributing
This project is available under the MIT license and contributions are welcomed. If you would like to contribute, please fork the repository and create a PR. We would be happy to review it and merge your contribution.